









Two cobots using the autonomous assessment rollout from Finetuned LBM to long-delayed behavior like installing a bike rotor. , Source: Toyota Research Institute
The Toyota Research Institute (TRI) released its study results on the large behavior model (LBMS) this week, which can be used to train general-purpose robots. The study showed that a single LBM can learn hundreds of tasks and use pre -knowledge to achieve new skills with 80% less training data.
LBMs are shown on large, diverse manipulation datasets. Despite their growing popularity, the robotics community surprisingly knows very little about the nuances of LBM offering. TRAI With this study, light works on the recent progress in algorithm and dataset design.
In all, TRAI stated that its findings largely support the recent bounc in the popularity of the LBM-style robot foundation model, evidence that large-scale pretering on diverse robot data is a viable route for more capable robots, although with some points of caution.
General-purpose robots promise a future where domestic robots can provide everyday assistance. However, we are not at the point where any robot can deal with average domestic functions. LBMS, or AII systems that take robot sensors in data and output actions can change it, it can change, Tri said.
In 2024, TRAI won one RBR50 Robotics Innovation Award Fast robot to create your work for teaching.
Overview of the findings of the three
https://www.youtube.com/watch?v=delpntgzjt4
TRAI trained a series of dissemination-based LBMs on about 1,700 hours of robot data and conducted 1,800 real-world evaluation rollouts and more than 47,000 simulation rollouts to dragging their capabilities strictly. It was found that LBMS:
- Distribute relative performance reforms relative to scratch policies
- Enable new tasks learned with 3-5 × low data in challenging settings requiring strengthening for various types of environmental factors
- Constant improvement with increasing presetting data
Even with a few hundred diverse hours of data, and only a few hundred demo per behavior, the performance jumped meaningfully, TRAI said. Pretraning provides frequent performance uplifting in advance than expected scales. Robot data is not yet an internet value, but the benefits appear long ago – a promising signal to enable data acquisition and enabling the virtuous cycles of bootstraped display, TRI claimed.
TRI’s evaluation suits include many novels and highly challenging long-shelter real-world functions; This settings fined and evaluated, LBM pretering improves performance despite excessive separation from the preparation functions of these behaviors.
Inside the architecture and data of LBM of TRAI
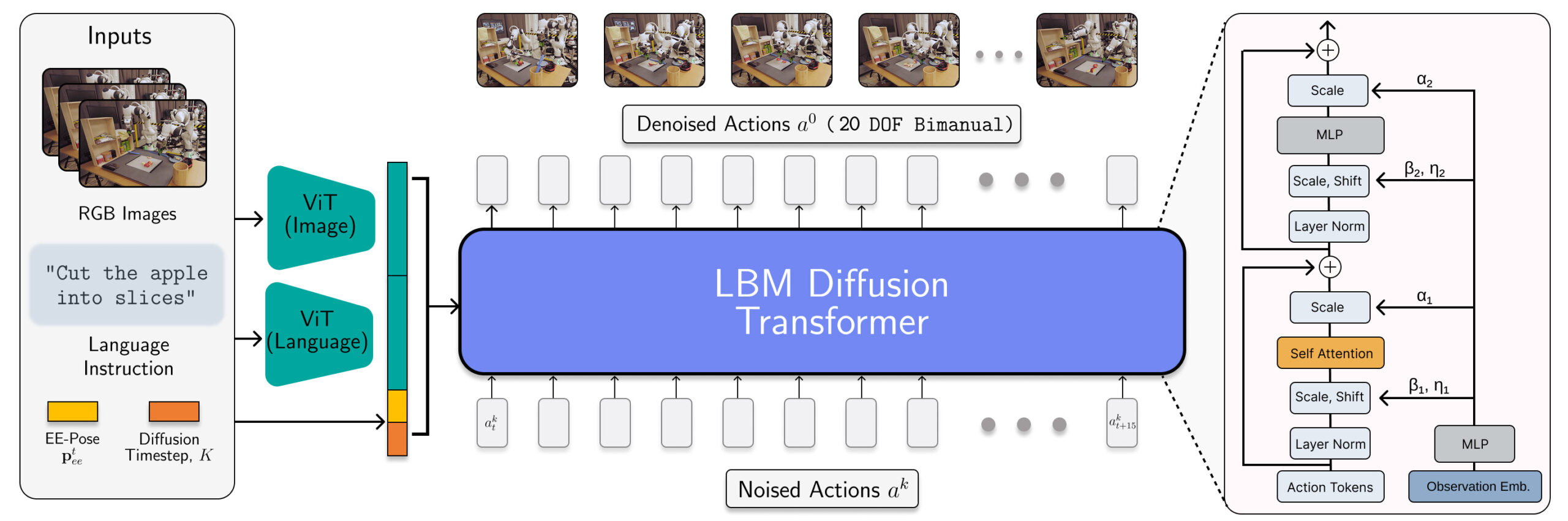
LBM architecture is accelerated as a spread transformer that predicts robot functions. , Source: Toyota Research Institute
Tri’s LBM is screened with multitask defusion policies and a transformer with an encoded heads on the encoded comments with multitask defusion policies with multimodal VIT-language encoders. These models consume wrist and visual cameras, robot proposesption, and language signs and predict 16 timsteps (1.6 seconds) action changes.
Researchers trained LBMs at a mixture of 468 hours internal bipolar robot teleoperation data, 45-hour simulation-across teleportation data, 32-hour universal manipulation interface (UMI) data, and an open ex-amboderent dataset at a mixture of about 1,150 hours.
While the proportion of simulation data is small, its inclusion in TRAI’s pretraying mixtures ensures that it can evaluate the same LBM checkpoint in both sim and real.
Ways of evaluation of three
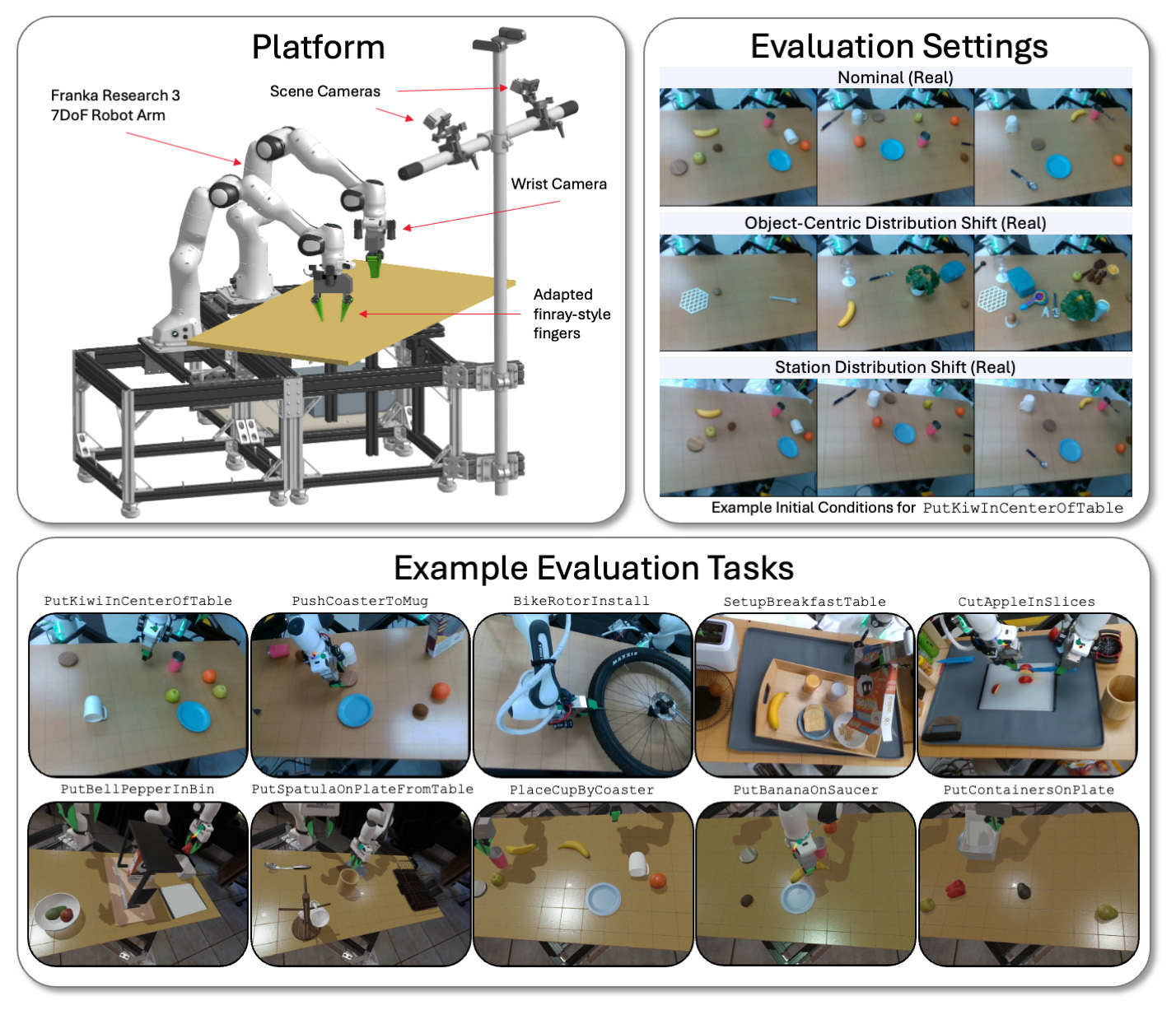
Tri evaluates its LBM model on a bipolar platform in various types of functions and environmental conditions in both simulation and real world. , Source: Toyota Research Institute
Tri Franca Panda FR3 up to two weapons and six cameras-up to two on each wrist, and evaluates its LBM at physical and drak-simulated bipolar stations that employ two static visual cameras.
It evaluates both the models on both viewed tasks (present in preterening data) and unseen tasks (which Tri uses to fix its pretress model). The TRI’s evaluation suit includes 16 simulated observed-durating-painting functions, 3 real-durious-durning-painting work, 5 first unseen long-term-long-Horizone simulated work, and 5 complex are included in the first-long-lasting-long-lasting-long-lasting-long-lasting-long-lasting-long-lasting-long-last-lastings
Each model was tested through 50 rollouts for each real -world work and 200 rollouts for each simulation work. This enables a high level of statistical hardness in our analysis, with a preetrad model assessed at 4,200 rollouts in 29 tasks.
TRAI said that it carefully controls the initial conditions to be consistent in both real world and simulation. It also performs blind A/B-style tests in the real world with statistical importance calculated through a sequential hypothesis test structure.
Many effects seen by the researchers were only average with large-to-standard sample size and careful statistical tests that are non-standard for empirical robotics. It is easy for noise due to experimental variation to dwarf the effects of measuring, and many robotics paper can measure statistical noise due to insufficient statistical power.
Top TAKEWAYS of Tri by Research
One of the team’s main Techauve It is that finished performance improves smoothly with increasing data. On the data scale we examined, Tri did not see any evidence of the dissection of the performance or sharp conflict points; Aye Scaling in robotics appears alive and well.
TRAI, however, experienced the results mixed with non-finette pretend LBMs. Encouraged, it was found that a single network is capable of learning several tasks simultaneously, but it does not observe frequent outperforms from uninterrupted tuning single-task training. TRAI hopes that this is partly due to the language stereability of its model.
In internal trials, TRAI stated that it has seen some promising early signs that large VLA prototypes remove some of this difficulty, but a high-linguistic model requires more work to strictly examine this effect in a high-linguistic model.
When it comes to the points of caution, TRI said that microscopic design such as data normalization can have a large impact on performance, often dominating architectural or algorithm changes. It is important that these design options are carefully isolated to avoid the source of performance changes.




